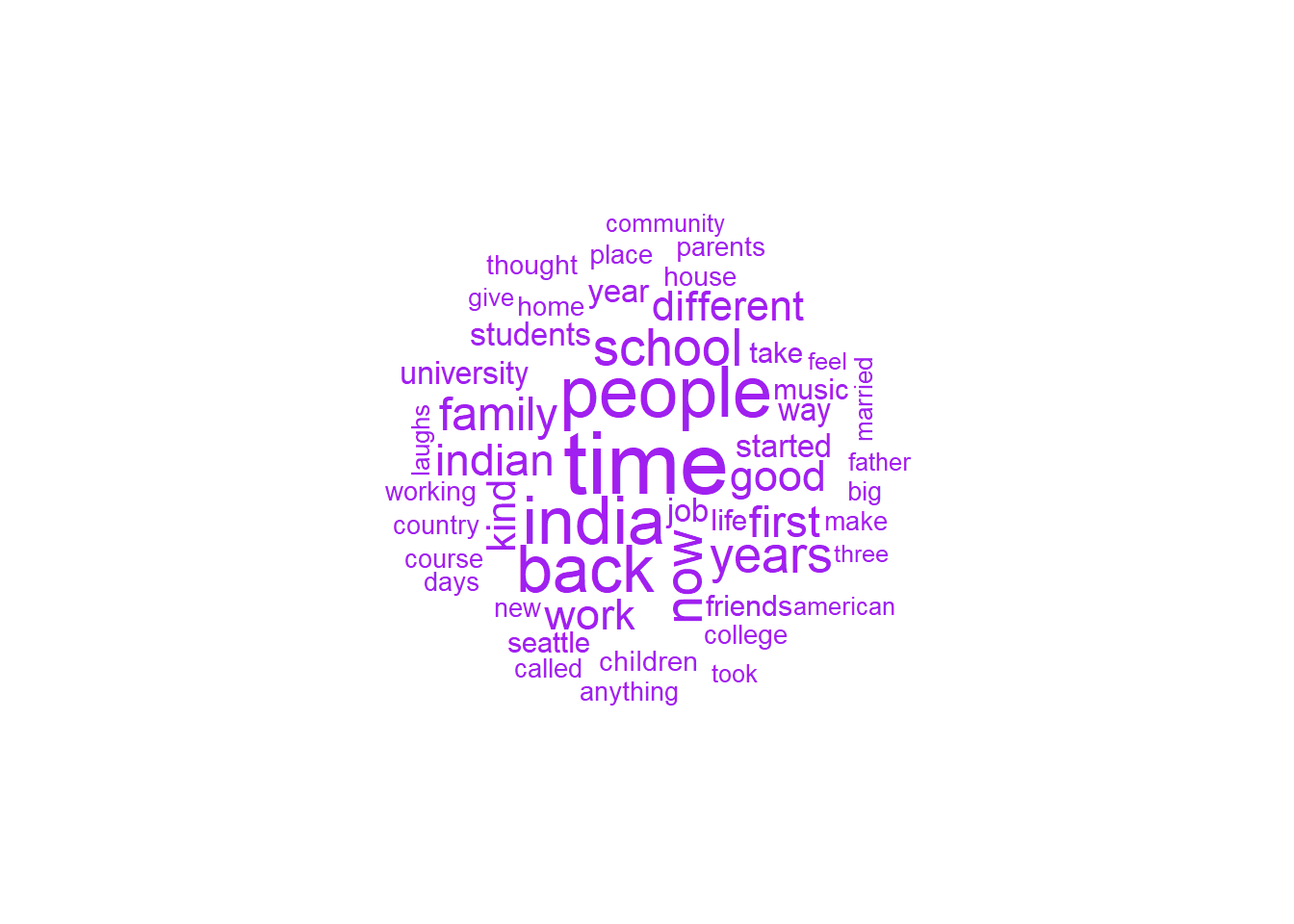In the first part of the post, I will revise some of the processing and preliminary analysis for the oral histories, which I worked on in the previous blog post. I will then work on generating and cleaning the Reddit data.
Oral Histories: Cleaning Data
# list out files.# file_list <- dir("~/Desktop/2022_Fall/GitHub/Text_as_Data_Fall_2022/posts/Transcripts", full.names = TRUE, pattern = "*.txt")# create list of text files.# transcripts <- readtext(paste0(file_list), docvarnames = c("transcript", "text"))# remove references to 'interviewer:' and 'interviewee:', as well as line breaks, '\n'. I found this website really helpful in testing out regex: https://spannbaueradam.shinyapps.io/r_regex_tester/# transcripts$text <- str_replace_all(transcripts$text, "[a-zA-Z]+:", "")# transcripts$text <- str_replace_all(transcripts$text, "\n", "")# saveRDS(transcripts, "transcripts.rds")# transcripts <- read_rds("transcripts.rds")# create 'quanteda' corpus. oh_corpus <-corpus(transcripts$text)# create my own list of stopwords, based on qualitative reading of the first transcript.to_keep <-c("do", "does", "did", "would", "should", "could", "ought", "isn't", "aren't", "wasn't", "weren't", "hasn't", "haven't", "hadn't", "doesn't", "don't", "didn't", "won't", "wouldn't", "shan't", "shouldn't", "can't", "cannot", "couldn't", "mustn't", "because", "against", "between", "into", "through", "during", "before", "after", "above", "below", "over", "under", "no", "nor", "not")Stopwords <-stopwords("en")Stopwords <- Stopwords[!(Stopwords %in% to_keep)]# create tokens, remove punctuation, numbers, symbols and stopwords, then convert to lowercase.oh_tokens <-tokens(oh_corpus, remove_punct = T, remove_numbers = T, remove_symbols = T)oh_tokens <-tokens_select(oh_tokens, pattern = Stopwords, selection ="remove")oh_tokens <-tokens_tolower(oh_tokens)# remove tokens that appeared in previous wordcloud that are not too meaningful.oh_tokens <-tokens_remove(oh_tokens, c("know", "even", "used", "thing", "lot", "yes", "say", "going", "went", "yeah", "come", "actually", "mean", "like", "think", "get", "go", "said", "see", "things", "really", "well", "still", "little", "got", "right", "can", "came", "um", "quite", "bit", "every", "oh", "many", "always", "one", "two", "just", "much", "want", "wanted", "okay", "part", "also", "just", "us", "never", "many", "something", "want", "wanted", "uh"))# get summary of corpus.oh_summary <-summary(oh_corpus)# add metadata on interview phase and interviewee gender.oh_summary$phase <-c(1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 4, 4, 4, 4, 4, 4, 4)oh_summary$gender <-c(1, 1, 1, 2, 1, 1, 2, 1, 2, 1, 1, 2, 1, 1, 2, 1, 1, 1, 2, 2, 2, 2, 1, 1, 1, 2, 1, 2, 1, 2, 2, 1, 1, 1, 2, 2, 2, 3, 1, 2, 2)# create metadata.docvars(oh_corpus) <- oh_summary
I changed up the wordcloud by removing some tokens that were not as meaningful, and this seems to paint a much clearer picture of what the interviews were about - work, music, college, family, friends, and moving to a new country.
The network plot also looks a lot better after removing symbols; it’s much more inter-connected. It looks like many interviews referenced Seattle, which makes sense, since the interviews were conducted by UW. Lots of references to work, school and university, which might reflect (1) South Asian cultural focus on these themes, or (2) possibly many of the migrants moved to the US for these purposes.
Oral Histories: N-Grams
Since the oral histories were collected over a number of years, there did not seem to be a uniform structure that they followed. Hence, I will randomly select a subset of transcripts, and then try to identify common phrases.
From the small selection of n-grams above, it seems like some topics that might arise are memories from South Asia, what prompted the move to the US (education, work), travel, experiences in the US, etc.
How do I preserve sequences of two or four numbers in my tokens? These might reference years in history, which might be important to understand some topics that come up.
Reddit: Generating Data
The previous time I tried to load the Reddit data, it just didn’t work. I’m going to try to leave RStudio alone for a longer time this time around and see if that might do the trick instead. Much of the code below is commented out, since it need not be re-run when rendering.
# generate top 1000 posts.# content_top <- find_thread_urls(subreddit="ABCDesis",period="all",sort_by="top")# content_top <- content_top[-1,]# content_top$type <- "top"# saveRDS(content_top, "content_top.rds")# content_top <- read_rds("content_top.rds")# attempting to generate comments alone first - this took ~ 1hr.# url_content <- get_thread_content(content$url[1:1000])$comments$comment# saveRDS(url_content, "url_content.rds")# url_content_top <- read_rds("url_content.rds")# i decided to try to get additional info on the comments as well.# url_content_info <- get_thread_content(content$url[1:1000])$comments# saveRDS(url_content_info, "url_content_info.rds")# url_content_info_top <- read_rds("url_content_info.rds")# url_content_info_top$type <- "top"# saveRDS(url_content_info_top, "url_content_info_top.rds")# comments_top <- read_rds("url_content_info_top.rds")# dr. song also wanted me to try generating more than 1000 posts, so i'm gonna try to create tables for 'hot' and 'rising' as well, not just 'top'.# content_hot <- find_thread_urls(subreddit="ABCDesis",period="all",sort_by="hot")# content_hot$id <- 1:991# check duplicates with top posts, then remove them.# duplicates <- inner_join(content_hot, content_top)# remove_list <- duplicates$id# content_hot <- content_hot %>% slice(-c(remove_list))# save object.# content_hot$type <- "hot"# saveRDS(content_hot, "content_hot.rds")# content_hot <- read_rds("content_hot.rds")# generate comments for 'hot' posts.# comments_hot <- get_thread_content(content_hot$url[1:936])$comments# comments_hot$type <- "hot" # saveRDS(comments_hot, "comments_hot.rds")# comments_hot <- read_rds("comments_hot.rds")# ok, i'm not going to add rising' or 'new', because 'rising' only had 24 posts, and 'new' had many duplicates with 'hot'. so i'll just be using 'hot' and 'top' posts.# combine 'hot' and 'top' posts into 1 dataframe.# content_hot <- content_hot[,-8]# reddit_posts <- rbind(content_hot, content_top)# saveRDS(reddit_posts, "reddit_posts.rds")# reddit_posts <- read_rds("reddit_posts.rds")# combine 'hot' and 'top' comments into 1 dataframe.# reddit_comments <- rbind(comments_hot, comments_top)# saveRDS(reddit_comments, "reddit_comments.rds")# reddit_comments <- read_rds("reddit_comments.rds")
Ok, this is a quick summary of what I’ve done above - I generated both the ‘top’ and ‘hot’ posts of all time from the subreddit, as well as all the comments on the posts, and some associated information. I then combined them into two dataframes - one with all the posts (N = 1,936) and another with all the comments (N = 110,967). I’m going to clean up the two dataframes in the following code chunk.
Reddit: Cleaning Data
# check dataframe of comments.glimpse(reddit_comments)
# remove 'upvotes' and 'downvotes' as they haves no useful info.reddit_comments <- reddit_comments %>%select (-c(upvotes, downvotes))
Error in `select()`:
! Can't subset columns that don't exist.
✖ Column `upvotes` doesn't exist.
# remove 'deleted' / 'removed' comments.reddit_comments$comment <-str_replace_all(reddit_comments$comment, "\\[deleted\\]", "")reddit_comments$comment <-str_replace_all(reddit_comments$comment, "\\[ Removed by Reddit \\]", "")reddit_comments <- reddit_comments[!(reddit_comments$comment==""), ]# create a vectorized function to remove html elements from comments.# vectorized_htmldecode <- Vectorize(HTMLdecode)# run the function - this is commented out because it took a really long time. # reddit_comments$comment <- vectorized_htmldecode(reddit_comments$comment)# i'm going to save the object so i don't have to re-do this.# saveRDS(reddit_comments, "reddit_comments_final.rds")# re-load the object.# reddit_comments_final <- read_rds("reddit_comments_final.rds")# ok, now check the dataframe of posts.glimpse(reddit_posts)
Rows: 1,936
Columns: 7
$ date_utc <chr> "2022-09-05", "2022-09-06", "2022-09-05", "2022-09-05", "202…
$ timestamp <dbl> 1662405203, 1662431521, 1662394101, 1662350088, 1662419582, …
$ title <chr> "What are some good hairstyles for guy that does have his be…
$ text <chr> "", "", "\n\n[View Poll](https://www.reddit.com/poll/x6jxfg)…
$ comments <dbl> 4, 2, 9, 25, 12, 16, 4, 3, 0, 0, 4, 80, 9, 0, 85, 15, 24, 11…
$ url <chr> "https://www.reddit.com/r/ABCDesis/comments/x6oivc/what_are_…
$ type <chr> "hot", "hot", "hot", "hot", "hot", "hot", "hot", "hot", "hot…
Error in `select()`:
! Can't subset columns that don't exist.
✖ Column `subreddit` doesn't exist.
# remove html elements from 'title' column.# reddit_posts$title <- vectorized_htmldecode(reddit_posts$title)# remove html elements from 'text' column.# reddit_posts$text <- vectorized_htmldecode(reddit_posts$text)# save the finalised posts object.# saveRDS(reddit_posts, "reddit_posts_final.rds")# re-load the object.# reddit_posts_final <- read_rds("reddit_posts_final.rds")
Reddit: Text Plots
# create 'quanteda' corpus. reddit_corpus <-corpus(reddit_comments_final$comment)# use same list of stopwords as oral histories.to_keep <-c("do", "does", "did", "would", "should", "could", "ought", "isn't", "aren't", "wasn't", "weren't", "hasn't", "haven't", "hadn't", "doesn't", "don't", "didn't", "won't", "wouldn't", "shan't", "shouldn't", "can't", "cannot", "couldn't", "mustn't", "because", "against", "between", "into", "through", "during", "before", "after", "above", "below", "over", "under", "no", "nor", "not")Stopwords <-stopwords("en")Stopwords <- Stopwords[!(Stopwords %in% to_keep)]# create tokens, remove punctuation, numbers, symbols and stopwords, then convert to lowercase.reddit_tokens <-tokens(reddit_corpus, remove_punct = T, remove_numbers = T, remove_symbols = T)reddit_tokens <-tokens_select(reddit_tokens, pattern = Stopwords, selection ="remove")reddit_tokens <-tokens_tolower(reddit_tokens)# remove tokens that appear in wordcloud that are not too meaningful.reddit_tokens <-tokens_remove(reddit_tokens, c("m", "s", "say", "see", "make", "way", "well", "many", "someone", "never", "still", "now", "go", "thing", "things", "know", "think", "also", "said", "going", "want", "t", "one", "lot", "much", "even", "really", "sure", "yeah", "look", "always", "something", "re", "actually", "get", "got", "though", "take", "etc", "can", "like", "don", "saying"))# get summary of corpus.reddit_summary <-summary(reddit_corpus)# create wordcloud with modified data.reddit_dfm <- reddit_tokens %>%dfm() %>%dfm_remove(stopwords("en"))textplot_wordcloud(reddit_dfm, max_words =50, color="purple")
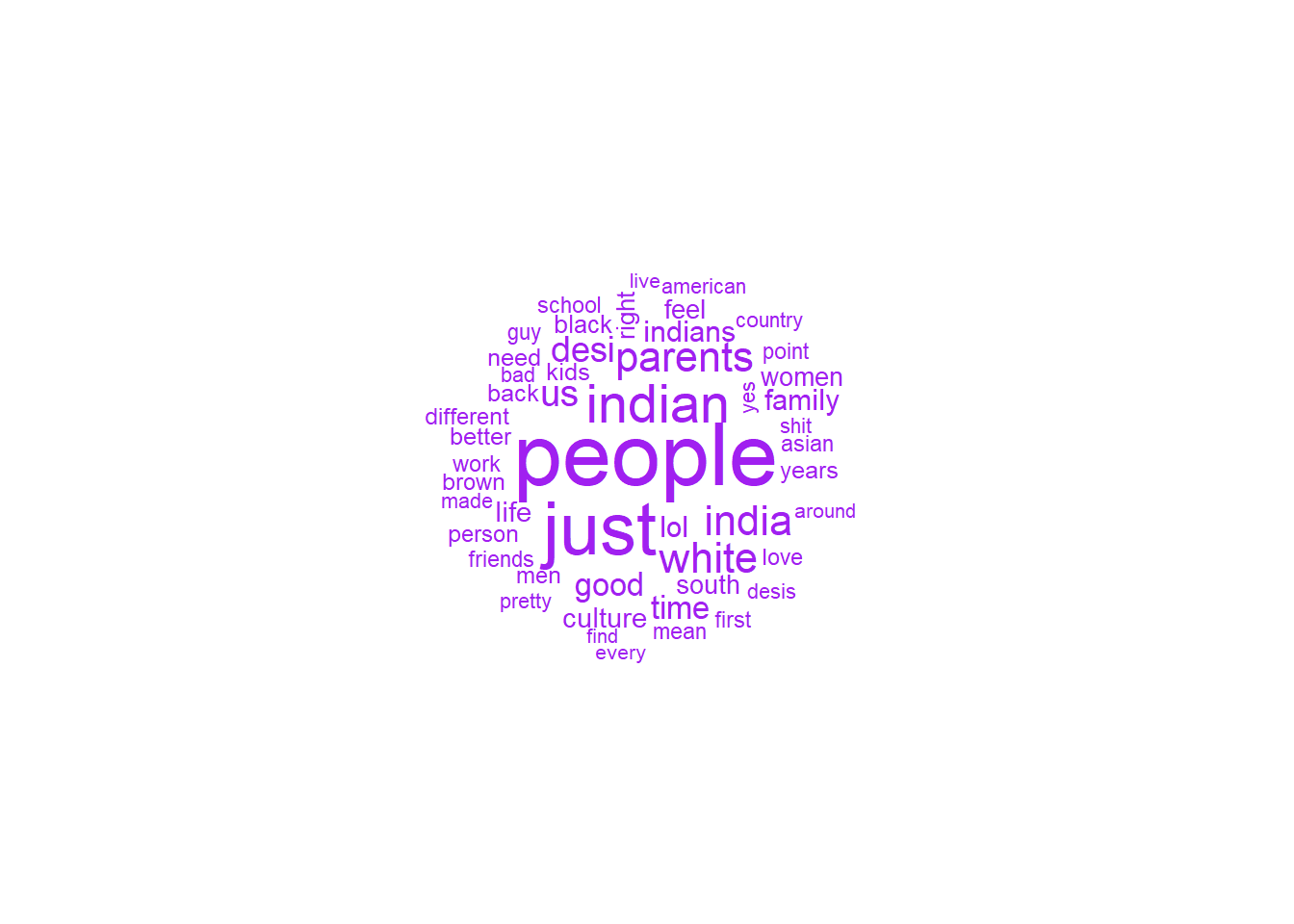
The wordcloud and network plot allow me to confirm that this subreddit indeed discusses South Asian culture, hence making it a good comparison with the oral histories data. We can also see that the younger generation has concerns specific to their age group - such as with dating and relationships, a wider range of ethnic and national groups (Asians, Black people, White people, British, etc), racism (which was not in the text plots for the older generation) and even caste concerns. This gives me some idea of how the values and concerns of South Asians have changed over time, which is my first research question.
Comparing the Two Datasets
I will attempt to use str_match() to compare how many times ‘culture’ appears in the oral histories vs. Reddit data (as a proportion of the total number of tokens).
# compute proportions for reddit data.sum(str_count(reddit_tokens, "[cC]ultur"))
[1] 8047
sum(ntoken(reddit_tokens))
[1] 2029966
# compute proportions for oral histories.sum(str_count(oh_tokens, "[cC]ultur"))
[1] 502
sum(ntoken(oh_tokens))
[1] 206015
# test proportions.prop.test(x =c(8047, 502), n =c(2029966, 206015), p =NULL, alternative ="two.sided", correct =TRUE)
2-sample test for equality of proportions with continuity correction
data: c(8047, 502) out of c(2029966, 206015)
X-squared = 114.16, df = 1, p-value < 2.2e-16
alternative hypothesis: two.sided
95 percent confidence interval:
0.00129494 0.00175984
sample estimates:
prop 1 prop 2
0.003964106 0.002436716
# save.image("post4_saaradhaa.RData")
Interesting - the younger generation referenced culture significantly more than the older generation did.
Moving Forward
This is my tentative plan for the next two posts, which I might revise depending on time constraints.
Post 5: try Personal Values Dictionary on oral histories and Reddit data.
Post 6: do topic modelling on oral histories and Reddit data.
Source Code
---title: "Post 4"author: "Saaradhaa M"description: "Cleaning Reddit Data; Analysing PDFs and Reddit Data"date: "10/29/2022"editor: visualformat: html: df-print: paged toc: true code-copy: true code-tools: true css: "styles.css"categories: - post 4 - saaradhaa---```{r}#| label: setup#| warning: false#| message: falselibrary(tidyverse)library(stringr)library(quanteda)library(quanteda.textplots)library(readtext)library(phrasemachine)library(RedditExtractoR)library(readr)load("post4_saaradhaa.rdata")knitr::opts_chunk$set(echo =TRUE, warning =FALSE, message =FALSE)```## IntroductionIn the first part of the post, I will revise some of the processing and preliminary analysis for the oral histories, which I worked on in the previous blog post. I will then work on generating and cleaning the Reddit data.## Oral Histories: Cleaning Data```{r}# list out files.# file_list <- dir("~/Desktop/2022_Fall/GitHub/Text_as_Data_Fall_2022/posts/Transcripts", full.names = TRUE, pattern = "*.txt")# create list of text files.# transcripts <- readtext(paste0(file_list), docvarnames = c("transcript", "text"))# remove references to 'interviewer:' and 'interviewee:', as well as line breaks, '\n'. I found this website really helpful in testing out regex: https://spannbaueradam.shinyapps.io/r_regex_tester/# transcripts$text <- str_replace_all(transcripts$text, "[a-zA-Z]+:", "")# transcripts$text <- str_replace_all(transcripts$text, "\n", "")# saveRDS(transcripts, "transcripts.rds")# transcripts <- read_rds("transcripts.rds")# create 'quanteda' corpus. oh_corpus <-corpus(transcripts$text)# create my own list of stopwords, based on qualitative reading of the first transcript.to_keep <-c("do", "does", "did", "would", "should", "could", "ought", "isn't", "aren't", "wasn't", "weren't", "hasn't", "haven't", "hadn't", "doesn't", "don't", "didn't", "won't", "wouldn't", "shan't", "shouldn't", "can't", "cannot", "couldn't", "mustn't", "because", "against", "between", "into", "through", "during", "before", "after", "above", "below", "over", "under", "no", "nor", "not")Stopwords <-stopwords("en")Stopwords <- Stopwords[!(Stopwords %in% to_keep)]# create tokens, remove punctuation, numbers, symbols and stopwords, then convert to lowercase.oh_tokens <-tokens(oh_corpus, remove_punct = T, remove_numbers = T, remove_symbols = T)oh_tokens <-tokens_select(oh_tokens, pattern = Stopwords, selection ="remove")oh_tokens <-tokens_tolower(oh_tokens)# remove tokens that appeared in previous wordcloud that are not too meaningful.oh_tokens <-tokens_remove(oh_tokens, c("know", "even", "used", "thing", "lot", "yes", "say", "going", "went", "yeah", "come", "actually", "mean", "like", "think", "get", "go", "said", "see", "things", "really", "well", "still", "little", "got", "right", "can", "came", "um", "quite", "bit", "every", "oh", "many", "always", "one", "two", "just", "much", "want", "wanted", "okay", "part", "also", "just", "us", "never", "many", "something", "want", "wanted", "uh"))# get summary of corpus.oh_summary <-summary(oh_corpus)# add metadata on interview phase and interviewee gender.oh_summary$phase <-c(1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 4, 4, 4, 4, 4, 4, 4)oh_summary$gender <-c(1, 1, 1, 2, 1, 1, 2, 1, 2, 1, 1, 2, 1, 1, 2, 1, 1, 1, 2, 2, 2, 2, 1, 1, 1, 2, 1, 2, 1, 2, 2, 1, 1, 1, 2, 2, 2, 3, 1, 2, 2)# create metadata.docvars(oh_corpus) <- oh_summary```## Oral Histories: Text Plots```{r}# re-create wordcloud with modified data.dfm <- oh_tokens %>%dfm() %>%dfm_trim(min_termfreq =10, verbose =FALSE, min_docfreq = .1, docfreq_type ="prop") %>%dfm_remove(stopwords("en"))textplot_wordcloud(dfm, max_words=50, color="purple")```I changed up the wordcloud by removing some tokens that were not as meaningful, and this seems to paint a much clearer picture of what the interviews were about - work, music, college, family, friends, and moving to a new country.```{r}# create fcm.fcm <-fcm(dfm)# keep only top features.small_fcm <-fcm_select(fcm, pattern =names(topfeatures(fcm, 50)), selection ="keep")# compute weights.size <-log(colSums(small_fcm))# create network.textplot_network(small_fcm, vertex_size = size /max(size) *4)```The network plot also looks a lot better after removing symbols; it's much more inter-connected. It looks like many interviews referenced Seattle, which makes sense, since the interviews were conducted by UW. Lots of references to work, school and university, which might reflect (1) South Asian cultural focus on these themes, or (2) possibly many of the migrants moved to the US for these purposes.## Oral Histories: N-GramsSince the oral histories were collected over a number of years, there did not seem to be a uniform structure that they followed. Hence, I will randomly select a subset of transcripts, and then try to identify common phrases.```{r}# randomly choose 10 out of 41 transcripts.set.seed(1)numbers <-sample(1:41, 10, replace=FALSE)documents <- transcripts$text[numbers]# generate phrases.phrases <-phrasemachine(documents, minimum_ngram_length =2, maximum_ngram_length =4, return_phrase_vectors =TRUE, return_tag_sequences =TRUE)phrases[[1]]$phrases[300:320]phrases[[2]]$phrases[300:320]phrases[[3]]$phrases[300:320]phrases[[4]]$phrases[300:320]phrases[[5]]$phrases[300:320]phrases[[6]]$phrases[300:320]phrases[[7]]$phrases[300:320]phrases[[8]]$phrases[300:320]phrases[[9]]$phrases[300:320]phrases[[10]]$phrases[300:320]# save.image("post4_saaradhaa.RData")```From the small selection of n-grams above, it seems like some topics that might arise are memories from South Asia, what prompted the move to the US (education, work), travel, experiences in the US, etc.**How do I preserve sequences of two or four numbers in my tokens? These might reference years in history, which might be important to understand some topics that come up.**## Reddit: Generating DataThe previous time I tried to load the Reddit data, it just didn't work. I'm going to try to leave RStudio alone for a longer time this time around and see if that might do the trick instead. Much of the code below is commented out, since it need not be re-run when rendering.```{r}# generate top 1000 posts.# content_top <- find_thread_urls(subreddit="ABCDesis",period="all",sort_by="top")# content_top <- content_top[-1,]# content_top$type <- "top"# saveRDS(content_top, "content_top.rds")# content_top <- read_rds("content_top.rds")# attempting to generate comments alone first - this took ~ 1hr.# url_content <- get_thread_content(content$url[1:1000])$comments$comment# saveRDS(url_content, "url_content.rds")# url_content_top <- read_rds("url_content.rds")# i decided to try to get additional info on the comments as well.# url_content_info <- get_thread_content(content$url[1:1000])$comments# saveRDS(url_content_info, "url_content_info.rds")# url_content_info_top <- read_rds("url_content_info.rds")# url_content_info_top$type <- "top"# saveRDS(url_content_info_top, "url_content_info_top.rds")# comments_top <- read_rds("url_content_info_top.rds")# dr. song also wanted me to try generating more than 1000 posts, so i'm gonna try to create tables for 'hot' and 'rising' as well, not just 'top'.# content_hot <- find_thread_urls(subreddit="ABCDesis",period="all",sort_by="hot")# content_hot$id <- 1:991# check duplicates with top posts, then remove them.# duplicates <- inner_join(content_hot, content_top)# remove_list <- duplicates$id# content_hot <- content_hot %>% slice(-c(remove_list))# save object.# content_hot$type <- "hot"# saveRDS(content_hot, "content_hot.rds")# content_hot <- read_rds("content_hot.rds")# generate comments for 'hot' posts.# comments_hot <- get_thread_content(content_hot$url[1:936])$comments# comments_hot$type <- "hot" # saveRDS(comments_hot, "comments_hot.rds")# comments_hot <- read_rds("comments_hot.rds")# ok, i'm not going to add rising' or 'new', because 'rising' only had 24 posts, and 'new' had many duplicates with 'hot'. so i'll just be using 'hot' and 'top' posts.# combine 'hot' and 'top' posts into 1 dataframe.# content_hot <- content_hot[,-8]# reddit_posts <- rbind(content_hot, content_top)# saveRDS(reddit_posts, "reddit_posts.rds")# reddit_posts <- read_rds("reddit_posts.rds")# combine 'hot' and 'top' comments into 1 dataframe.# reddit_comments <- rbind(comments_hot, comments_top)# saveRDS(reddit_comments, "reddit_comments.rds")# reddit_comments <- read_rds("reddit_comments.rds")```Ok, this is a quick summary of what I've done above - I generated both the 'top' and 'hot' posts of all time from the subreddit, as well as all the comments on the posts, and some associated information. I then combined them into two dataframes - one with all the posts (*N* = 1,936) and another with all the comments (*N* = 110,967). I'm going to clean up the two dataframes in the following code chunk.## Reddit: Cleaning Data```{r}# check dataframe of comments.glimpse(reddit_comments)# remove 'upvotes' and 'downvotes' as they haves no useful info.reddit_comments <- reddit_comments %>%select (-c(upvotes, downvotes))# remove 'deleted' / 'removed' comments.reddit_comments$comment <-str_replace_all(reddit_comments$comment, "\\[deleted\\]", "")reddit_comments$comment <-str_replace_all(reddit_comments$comment, "\\[ Removed by Reddit \\]", "")reddit_comments <- reddit_comments[!(reddit_comments$comment==""), ]# create a vectorized function to remove html elements from comments.# vectorized_htmldecode <- Vectorize(HTMLdecode)# run the function - this is commented out because it took a really long time. # reddit_comments$comment <- vectorized_htmldecode(reddit_comments$comment)# i'm going to save the object so i don't have to re-do this.# saveRDS(reddit_comments, "reddit_comments_final.rds")# re-load the object.# reddit_comments_final <- read_rds("reddit_comments_final.rds")# ok, now check the dataframe of posts.glimpse(reddit_posts)# remove 'subreddit' column.reddit_posts <- reddit_posts %>%select (-c(subreddit))# remove html elements from 'title' column.# reddit_posts$title <- vectorized_htmldecode(reddit_posts$title)# remove html elements from 'text' column.# reddit_posts$text <- vectorized_htmldecode(reddit_posts$text)# save the finalised posts object.# saveRDS(reddit_posts, "reddit_posts_final.rds")# re-load the object.# reddit_posts_final <- read_rds("reddit_posts_final.rds")```## Reddit: Text Plots```{r}# create 'quanteda' corpus. reddit_corpus <-corpus(reddit_comments_final$comment)# use same list of stopwords as oral histories.to_keep <-c("do", "does", "did", "would", "should", "could", "ought", "isn't", "aren't", "wasn't", "weren't", "hasn't", "haven't", "hadn't", "doesn't", "don't", "didn't", "won't", "wouldn't", "shan't", "shouldn't", "can't", "cannot", "couldn't", "mustn't", "because", "against", "between", "into", "through", "during", "before", "after", "above", "below", "over", "under", "no", "nor", "not")Stopwords <-stopwords("en")Stopwords <- Stopwords[!(Stopwords %in% to_keep)]# create tokens, remove punctuation, numbers, symbols and stopwords, then convert to lowercase.reddit_tokens <-tokens(reddit_corpus, remove_punct = T, remove_numbers = T, remove_symbols = T)reddit_tokens <-tokens_select(reddit_tokens, pattern = Stopwords, selection ="remove")reddit_tokens <-tokens_tolower(reddit_tokens)# remove tokens that appear in wordcloud that are not too meaningful.reddit_tokens <-tokens_remove(reddit_tokens, c("m", "s", "say", "see", "make", "way", "well", "many", "someone", "never", "still", "now", "go", "thing", "things", "know", "think", "also", "said", "going", "want", "t", "one", "lot", "much", "even", "really", "sure", "yeah", "look", "always", "something", "re", "actually", "get", "got", "though", "take", "etc", "can", "like", "don", "saying"))# get summary of corpus.reddit_summary <-summary(reddit_corpus)# create wordcloud with modified data.reddit_dfm <- reddit_tokens %>%dfm() %>%dfm_remove(stopwords("en"))textplot_wordcloud(reddit_dfm, max_words =50, color="purple")# create fcm.reddit_fcm <-fcm(reddit_dfm)# keep only top features.small_reddit_fcm <-fcm_select(reddit_fcm, pattern =names(topfeatures(reddit_fcm, 50)), selection ="keep")# compute weights.size <-log(colSums(small_reddit_fcm))# create network.textplot_network(small_reddit_fcm, vertex_size = size /max(size) *4)```The wordcloud and network plot allow me to confirm that this subreddit indeed discusses South Asian culture, hence making it a good comparison with the oral histories data. We can also see that the younger generation has concerns specific to their age group - such as with dating and relationships, a wider range of ethnic and national groups (Asians, Black people, White people, British, etc), racism (which was not in the text plots for the older generation) and even caste concerns. This gives me some idea of how the values and concerns of South Asians have changed over time, which is my first research question.## Comparing the Two DatasetsI will attempt to use str_match() to compare how many times 'culture' appears in the oral histories vs. Reddit data (as a proportion of the total number of tokens).```{r}# compute proportions for reddit data.sum(str_count(reddit_tokens, "[cC]ultur"))sum(ntoken(reddit_tokens))# compute proportions for oral histories.sum(str_count(oh_tokens, "[cC]ultur"))sum(ntoken(oh_tokens))# test proportions.prop.test(x =c(8047, 502), n =c(2029966, 206015), p =NULL, alternative ="two.sided", correct =TRUE)# save.image("post4_saaradhaa.RData")```Interesting - the younger generation referenced culture significantly more than the older generation did.## Moving ForwardThis is my tentative plan for the next two posts, which I might revise depending on time constraints.- Post 5: try Personal Values Dictionary on oral histories and Reddit data.- Post 6: do topic modelling on oral histories and Reddit data.