library(tidyverse)
library(quanteda)
library(quanteda.textplots)
library(quanteda.dictionaries)
library(utils)
load("post5_saaradhaa.rdata")
knitr::opts_chunk$set(echo = TRUE, warning = FALSE, message = FALSE)Post 5
post 5
saaradhaa
KWIC and Dictionary Analysis
KWIC Analysis
I will first work on the comments I received for Post 4. I compared the appearance of the term ‘culture’ in the oral histories vs. Reddit comments, but received feedback to try a kwic analysis instead (to check which terms are more likely to be used with ‘culture’).
# load saved R object with oral histories.
# transcripts <- read_rds("transcripts.rds")
# create 'quanteda' corpus.
oh_corpus <- corpus(transcripts$text)
# create my own list of stopwords, based on qualitative reading of the first transcript.
to_keep <- c("do", "does", "did", "would", "should", "could", "ought", "isn't", "aren't", "wasn't", "weren't", "hasn't", "haven't", "hadn't", "doesn't", "don't", "didn't", "won't", "wouldn't", "shan't", "shouldn't", "can't", "cannot", "couldn't", "mustn't", "because", "against", "between", "into", "through", "during", "before", "after", "above", "below", "over", "under", "no", "nor", "not")
Stopwords <- stopwords("en")
Stopwords <- Stopwords[!(Stopwords %in% to_keep)]
# create tokens, remove punctuation, numbers, symbols and stopwords, then convert to lowercase.
oh_tokens <- tokens(oh_corpus, remove_punct = T, remove_numbers = T, remove_symbols = T)
oh_tokens <- tokens_select(oh_tokens, pattern = Stopwords, selection = "remove")
oh_tokens <- tokens_tolower(oh_tokens)
# remove tokens that appeared in previous wordcloud that are not too meaningful.
oh_tokens <- tokens_remove(oh_tokens, c("know", "even", "used", "thing", "lot", "yes", "say", "going", "went", "yeah", "come", "actually", "mean", "like", "think", "get", "go", "said", "see", "things", "really", "well", "still", "little", "got", "right", "can", "came", "um", "quite", "bit", "every", "oh", "many", "always", "one", "two", "just", "much", "want", "wanted", "okay", "part", "also", "just", "us", "never", "many", "something", "want", "wanted", "uh"))
# look at kwic for oral histories.
data <- kwic(oh_tokens, pattern = c("[cC]ultur"), window=15, valuetype = "regex")
textplot_xray(data)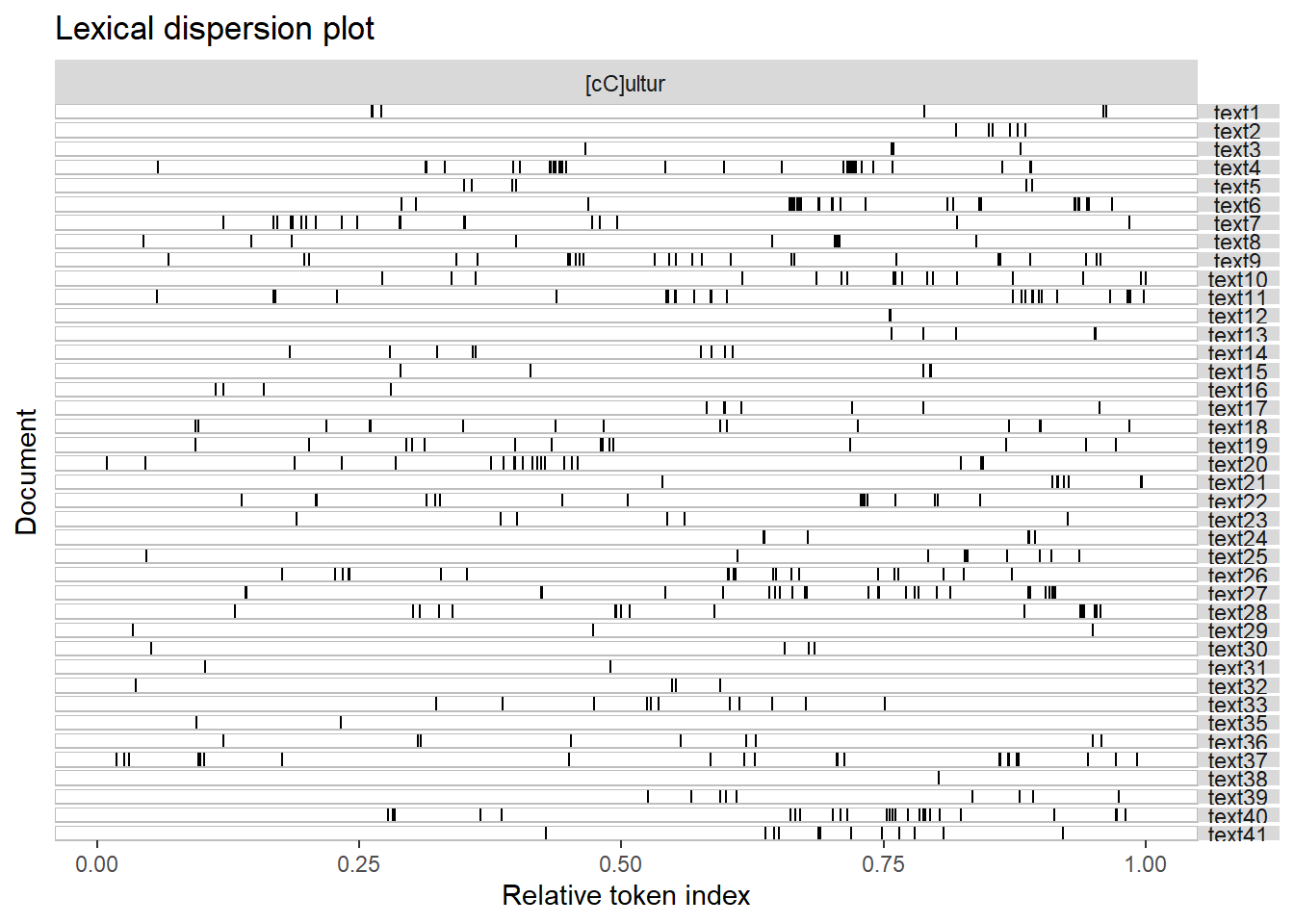
I am not too sure how to interpret this plot and might need some help with this.
# load saved R object with reddit data and create corpus. remove punctuation/symbols, lowercase.
# reddit_comments_final <- read_rds("reddit_comments_final.rds")
reddit_corpus <- corpus(reddit_comments_final$comment)
# use same list of stopwords as oral histories.
to_keep <- c("do", "does", "did", "would", "should", "could", "ought", "isn't", "aren't", "wasn't", "weren't", "hasn't", "haven't", "hadn't", "doesn't", "don't", "didn't", "won't", "wouldn't", "shan't", "shouldn't", "can't", "cannot", "couldn't", "mustn't", "because", "against", "between", "into", "through", "during", "before", "after", "above", "below", "over", "under", "no", "nor", "not")
Stopwords <- stopwords("en")
Stopwords <- Stopwords[!(Stopwords %in% to_keep)]
# create tokens, remove punctuation, numbers, symbols and stopwords, then convert to lowercase.
reddit_tokens <- tokens(reddit_corpus, remove_punct = T, remove_numbers = T, remove_symbols = T)
reddit_tokens <- tokens_select(reddit_tokens, pattern = Stopwords, selection = "remove")
reddit_tokens <- tokens_tolower(reddit_tokens)
# remove tokens that appear in wordcloud that are not too meaningful.
reddit_tokens <- tokens_remove(reddit_tokens, c("m", "s", "say", "see", "make", "way", "well", "many", "someone", "never", "still", "now", "go", "thing", "things", "know", "think", "also", "said", "going", "want", "t", "one", "lot", "much", "even", "really", "sure", "yeah", "look", "always", "something", "re", "actually", "get", "got", "though", "take", "etc", "can", "like", "don", "saying"))
# look at kwic for reddit data.
data2 <- kwic(reddit_tokens, pattern = c("[cC]ultur"), window=15, valuetype = "regex")
# textplot_xray(data2)Unfortunately, RStudio crashes/hangs when I try to load the plot for the Reddit comments, as there are too many matches for the pattern (N = 8,047). How can I fix this?
Personal Values Dictionary
The main part of this post focuses on implementing the Personal Values Dictionary (PVD) on the oral histories and Reddit data. This dictionary was created by Ponizovskiy et al. (2020), based on the 10 fundamental values theorized by Schwartz (1992). These are shown in the figure below, which was taken from their paper:

I created the table below to briefly summarize what each value means, adapting the descriptions from Schwartz (2012):
| Value | Need For? (adapted from Schwartz, 2012) |
|---|---|
| Self-Direction | Independence |
| Stimulation | Excitement |
| Hedonism | Enjoyment |
| Achievement | Success |
| Power | Authority |
| Security | Safety |
| Conformity | Harmony |
| Tradition | Maintaining customs |
| Universalism | Peace |
| Benevolence | Group harmony |
The PVD was validated using both short-form text (e.g., social media status updates) and long-form text (e.g., essays), making it a good fit to extract values from both the oral histories and Reddit data. There were also consistent relationships between the personal values generated by the dictionary and those actually reported by participants.
Analyse Oral Histories
# load dictionary.
dic <- read.delim("Refined_dictionary.txt", col.names=c("word","sentiment"))
# remove legend.
dic <- dic[12:1079, ]
# recode values for 'sentiment' column.
dic$sentiment <- recode(dic$sentiment, "1" = "SE", "2" = "CO", "3" = "TR", "4" = "BE", "5" = "UN", "6" = "SD", "7" = "ST", "8" = "HE", "9" = "AC", "10" = "PO")
# change to dictionary format.
dic <- as.dictionary(dic)
# run analysis.
oh_values <- liwcalike(oh_corpus, dic)
# remove 'segment', which is redundant since 'docname' supplies the same info.
oh_values <- oh_values[,-2]
# obtain mean values across texts.
graph_values <- oh_values %>% select(6:15) %>% colMeans()
graph_values <- as_tibble(graph_values)
graph_values$label <- c("ac", "be", "co", "he", "po", "sd", "se", "st", "tr", "un")
# plot graph.
ggplot(graph_values, aes(x= reorder(label,value), y= value)) +
geom_point(size = 1.5, color = "purple", fill = alpha("pink", 0.4), alpha = 0.8, shape = 21, stroke = 2) +
geom_segment(aes(x = label, xend = label, y = 0, yend = value)) +
theme_minimal() +
labs(title = "Personal Values Extracted From Oral Histories", x = "Value", y = "Mean Percentage") +
geom_text(aes(label=sprintf("%0.2f", ..y..)), position=position_dodge(width=0.9), vjust=-0.93, size=3)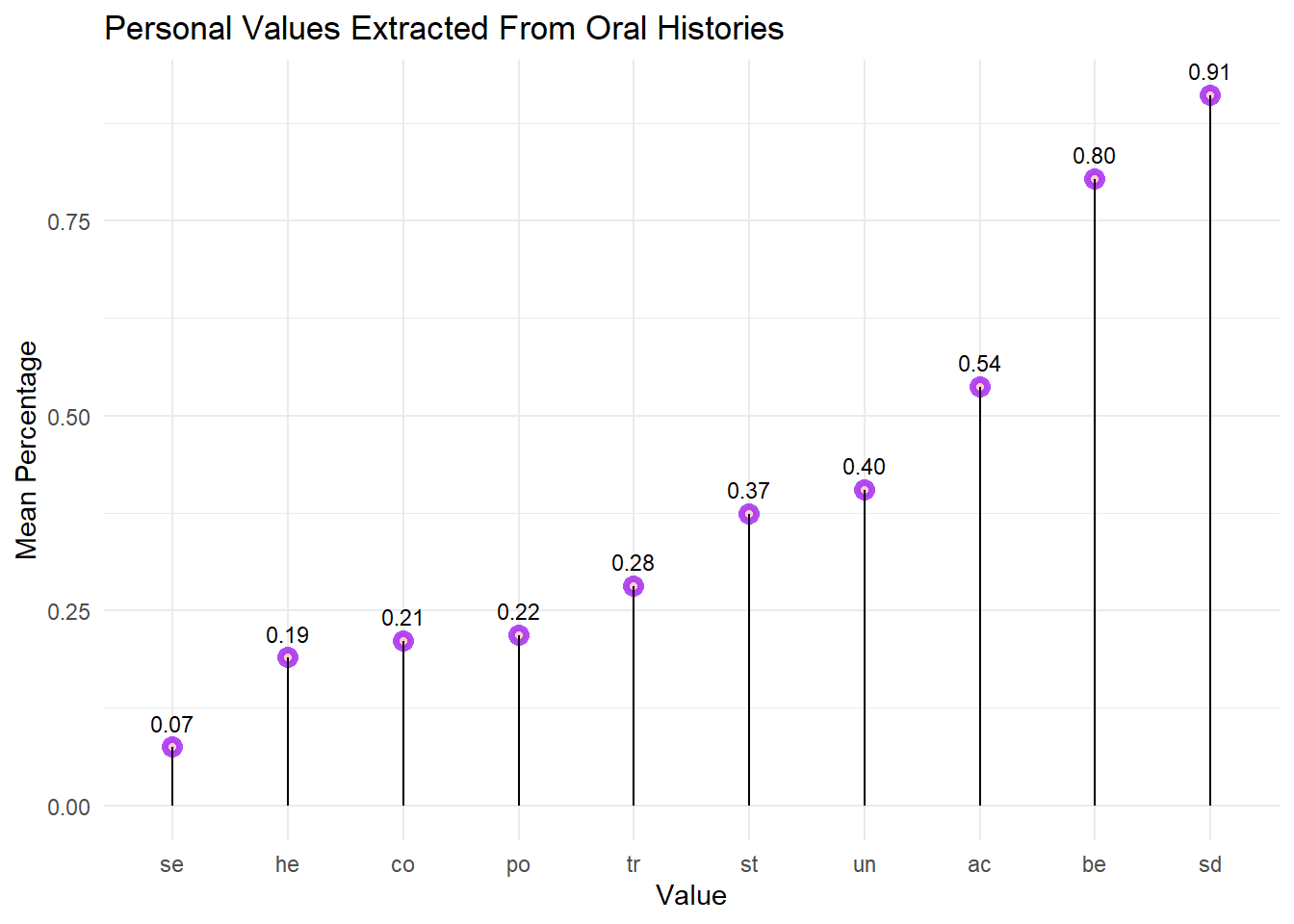
The top 3 values observed were self-direction, benevolence and achievement.
Analyse Reddit Comments
# run analysis.
reddit_values <- liwcalike(reddit_corpus, dic)
# remove 'segment', which is redundant since 'docname' supplies the same info.
reddit_values <- reddit_values[,-2]
# obtain mean values across texts.
values2 <- reddit_values %>% select(6:15) %>% colMeans()
values2 <- as_tibble(values2)
values2$label <- c("ac", "be", "co", "he", "po", "sd", "se", "st", "tr", "un")
# plot graph.
ggplot(values2, aes(x= reorder(label,value), y= value)) +
geom_point(size = 1.5, color = "purple", fill = alpha("pink", 0.4), alpha = 0.8, shape = 21, stroke = 2) +
geom_segment(aes(x = label, xend = label, y = 0, yend = value)) +
theme_minimal() +
labs(title = "Personal Values Extracted From Reddit", x = "Value", y = "Mean Percentage") +
geom_text(aes(label=sprintf("%0.2f", ..y..)), position=position_dodge(width=0.9), vjust=-0.93, size=3)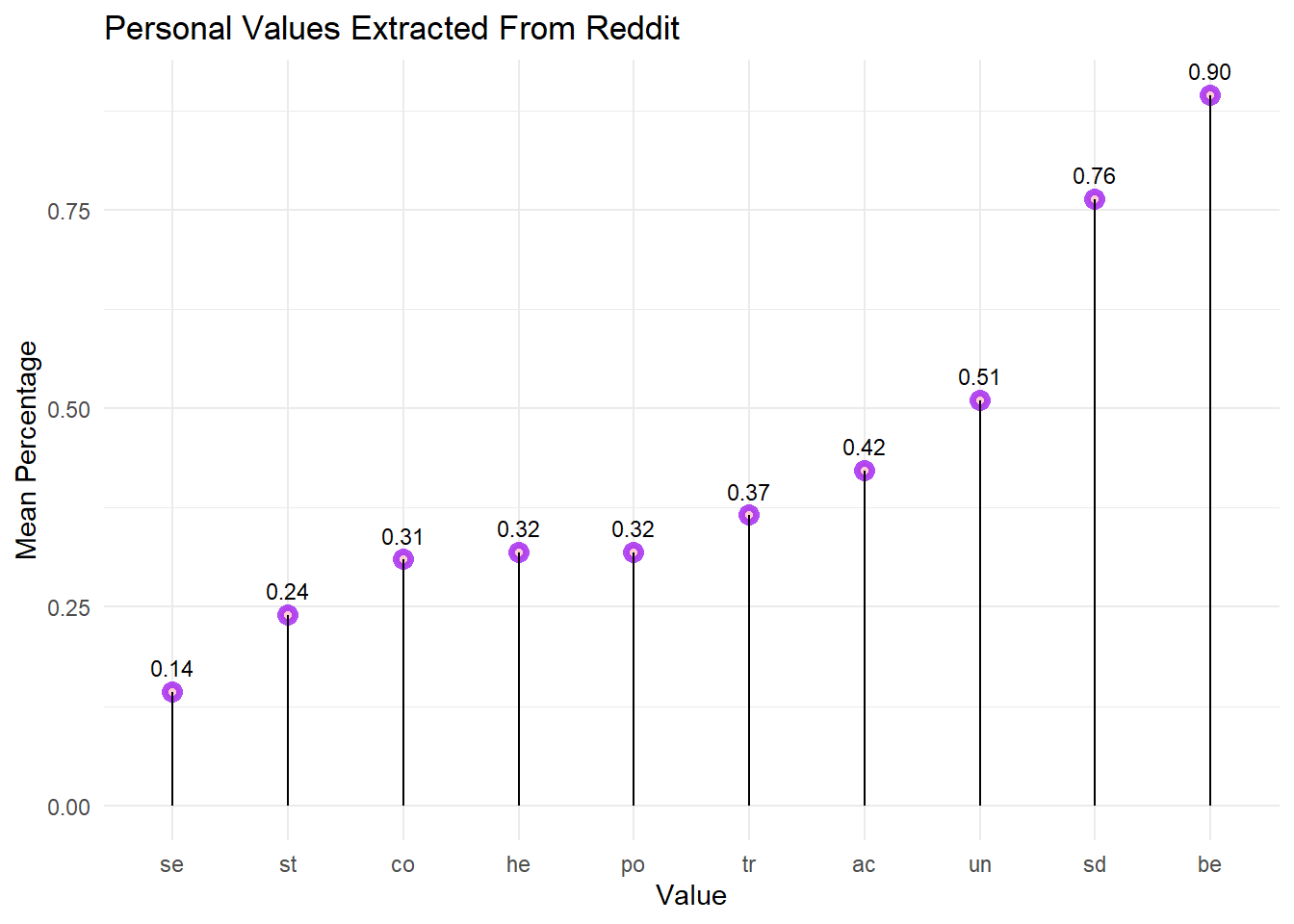
The top 3 values observed were benevolence, self-direction and universalism.
Impact on RQs
To recap, these are my RQs:
Research Questions
- How have the values and concerns of South Asian Americans changed over time?
- Do older South Asian Americans align more with the honour culture prevalent in their home countries? Do younger South Asian Americans align more with the dignity culture prevalent in the USA?
Self-direction and benevolence was common to both groups of South Asian Americans. This can be interpreted as representing dual needs for exploring the world independently, as well as protecting the well-being of close ones (Schwartz, 2012). These intuitively might not seem like they go together, but perhaps could be expected in migrants: leaving home to pursue new opportunities and adapt to a new culture, and caring for the small family unit brought over.
However, older South Asian Americans valued achievement more. Quoting directly from Schwartz (2012), p. 5: “personal success through demonstrating competence according to social standards…thereby obtaining social approval”. Assuming older South Asian Americans have largely been socialized to South Asian cultural values, we can interpret this as a need for success according to the societies they came from, so as to maintain their reputation. This is a key facet of honour cultures, as I described in Blog Post 1.
We can qualitatively skim the interview with the highest achievement score:
oh_values %>% select(docname,ac) %>% arrange(desc(ac)) %>% head(1)# save.image("post5_saaradhaa.RData")Opening Text 36 on my computer, the interviewee discusses her grueling training in classical dance, and how it was challenging to keep up with especially when she migrated to the US. This is a classic example of achievement.
Meanwhile, younger South Asian Americans valued universalism more. This is interesting, as Schwartz describes this as opposite to benevolence, which focuses just on loved ones: “people do not recognize these needs until they encounter others beyond the extended primary group…two subtypes of concern…welfare of those in the larger society and world and for nature”. This could reflect several things:
Younger South Asian Americans’ socialization to both South Asian and American cultures (regard for both the society at large and their close loved ones, reflected in endorsing supposedly opposing values);
Acknowledgment of growing social problems such as class inequality and global warming;
Greater socialization to the dignity culture in the US than their elders, a key facet of which entails recognizing the worth of every individual.
To caution, the above is just one potential interpretation of the results that makes sense to me. However, it’s important to note that honour and dignity are group-level values, while the PVD describes individual-level values. It is possible that there may be some disparities unaccounted for because of this.
Overall, the dictionary analysis allows us to partially answer the RQs:
- Values of South Asian Americans that remain unchanged are self-direction and benevolence, although the older generation gives more importance to the former and the younger generation gives more importance to the latter. Values that have changed: older South Asian Americans value achievement more, while younger South Asian Americans value universalism more.
- There is some potential evidence that older South Asian Americans align more with South Asian honour cultures, given the importance of achievement as endorsed by society; and that younger South Asian Americans align more with the US’ dignity culture, given the importance of universalism. The caveat is that both groups endorsed both values, but just at different degrees.
Bibliography
Ponizovskiy, V., Ardag, M., Grigoryan, L., Boyd, R., Dobewall, H., & Holtz, P. (2020). Development and Validation of the Personal Values Dictionary: A Theory–Driven Tool for Investigating References to Basic Human Values in Text. European Journal of Personality, 34(5), 885–902.
Schwartz, S. H. (1992). Universals in the content and structure of values: Theoretical advances and empirical tests in 20 countries. Advances in Experimental Social Psychology, 1–65.
Schwartz, S. H. (2012). An Overview of the Schwartz Theory of Basic Values. Online Readings in Psychology and Culture, 2(1).