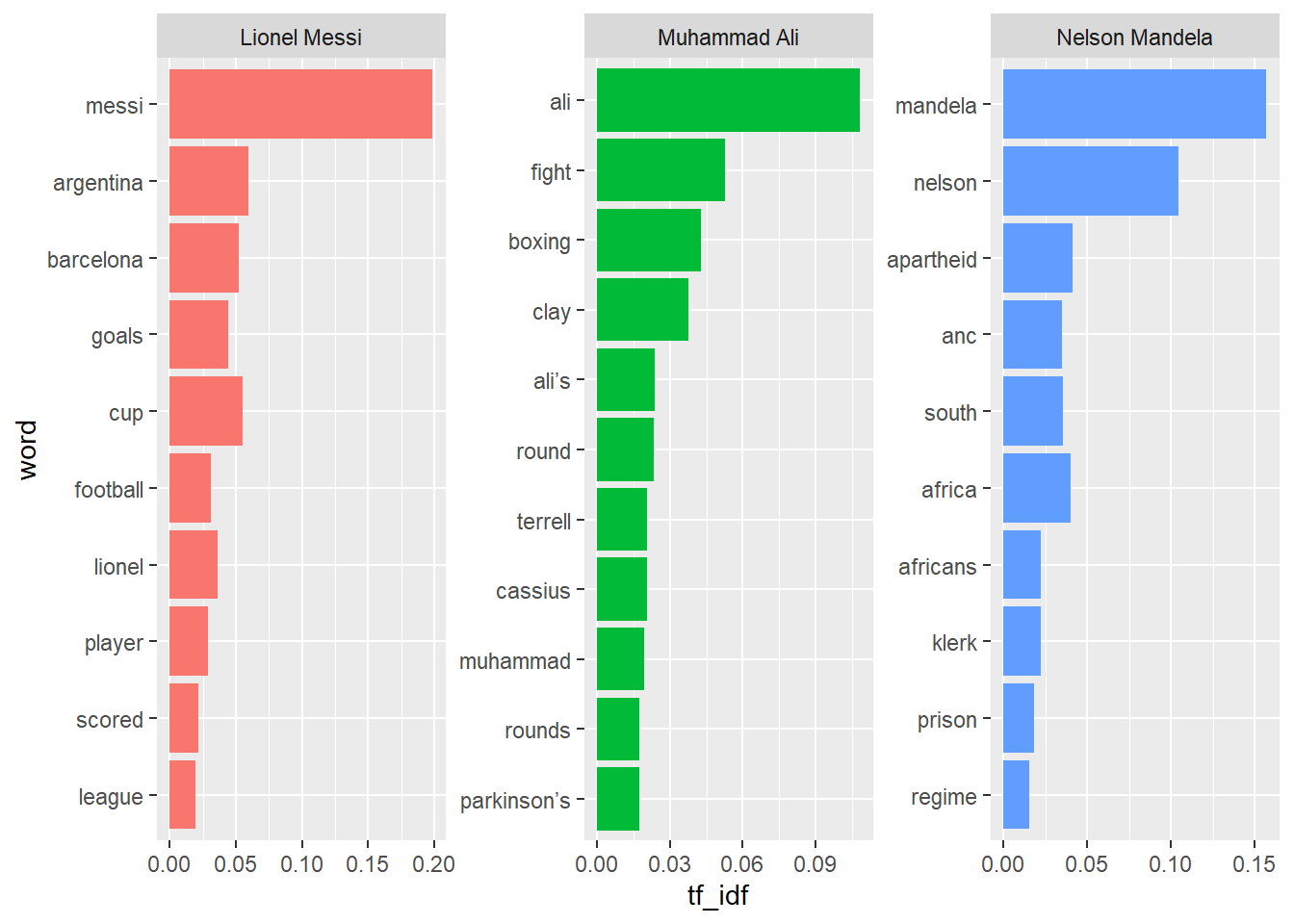
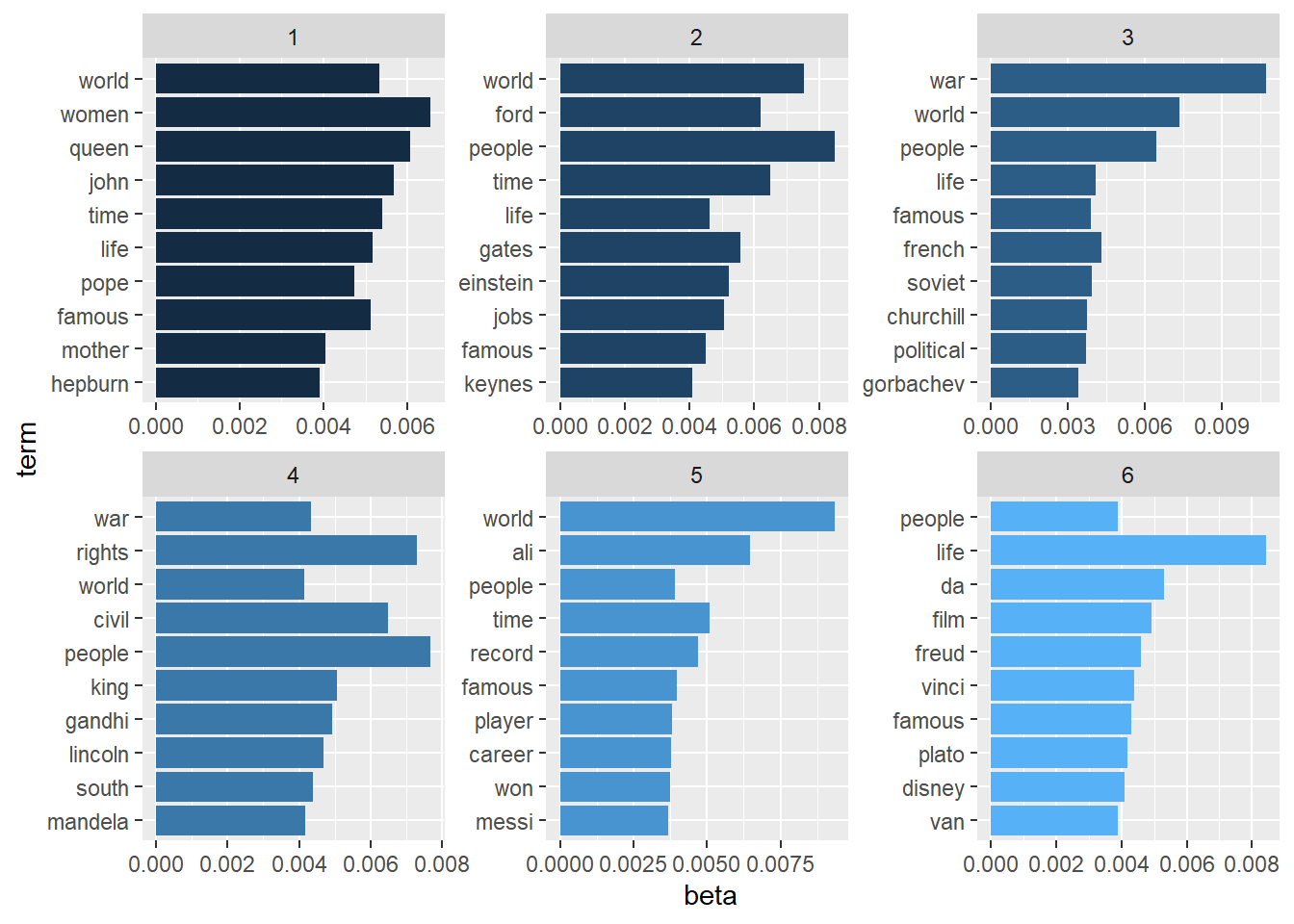
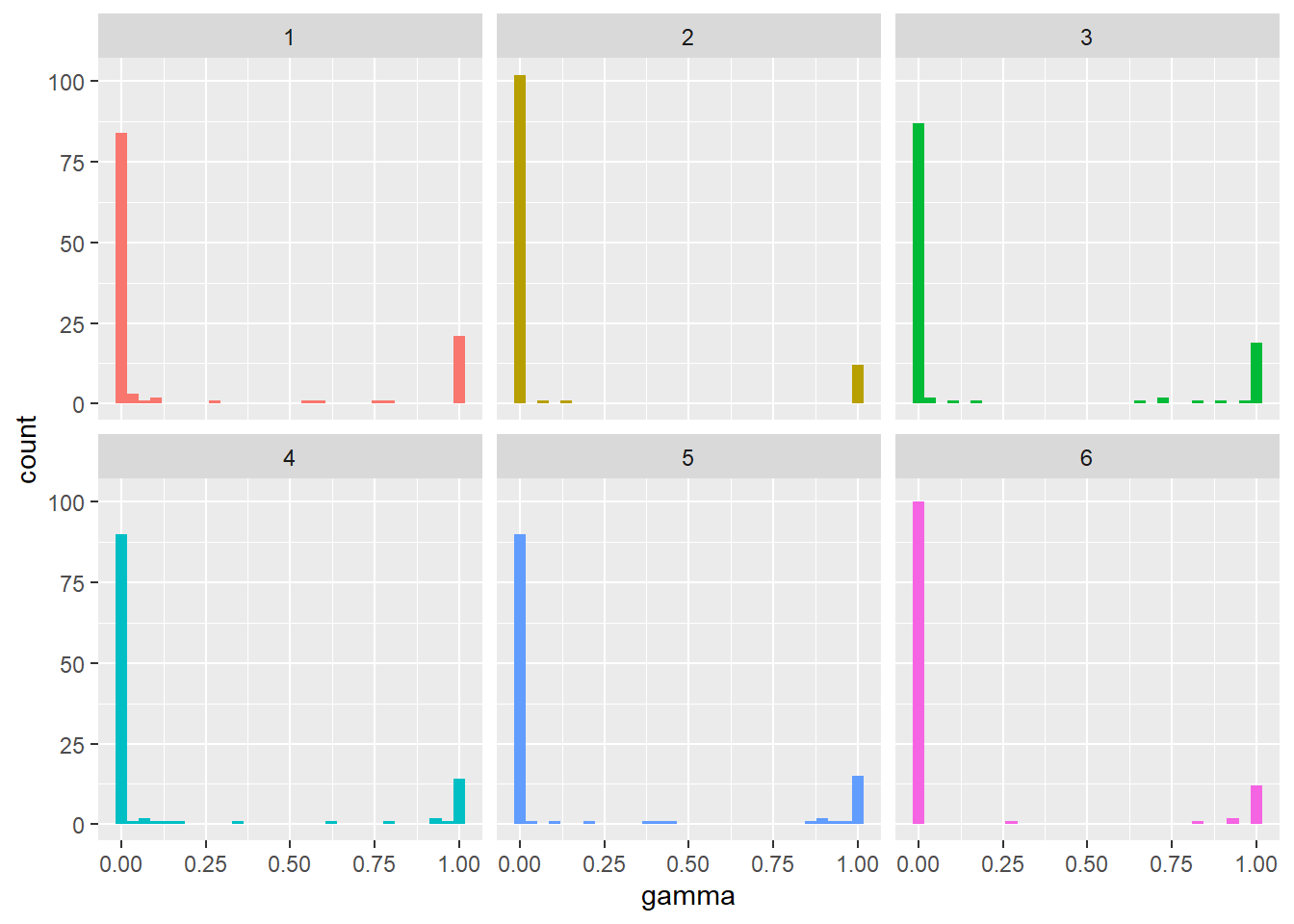
Topic 1 Top Words:
Highest Prob: women, queen, john, time, world, life, famous
FREX: magdalene, andrews, julie, pankhurst, j.k.rowling, amelia, anthony
Lift: 24th, andrews, baker, ballet, benedict, caesar’s, cleopatra’s
Score: audrey, hepburn, pope, wilde, magdalene, lennon, andrews
Topic 2 Top Words:
Highest Prob: people, world, time, ford, gates, einstein, jobs
FREX: web, apple, berners, baden, microsoft, hawking, computers
Lift: couzens, melinda, stewart’s, 1,000,000, 1,529, 1.25, 1.5
Score: web, berners, apple, baden, microsoft, keynes, hawking
Topic 3 Top Words:
Highest Prob: war, world, people, french, life, soviet, famous
FREX: bolivar, orwell, chanel, gaulle, putin, suu, kyi
Lift: 130george, 1755, 1766, 1778, 1781, 1783, 1785
Score: bolivar, orwell, chanel, castro, putin, gaulle, thatcher
Topic 4 Top Words:
Highest Prob: people, rights, civil, king, gandhi, lincoln, south
FREX: krugman, selassie, rosa, taliban, kennedy, mandela, haile
Lift: f.w, mohandas, vice, 16,000, 180after, 1842, 1850s
Score: krugman, tutu, parks, mandela, bus, selassie, luther
Topic 5 Top Words:
Highest Prob: world, ali, time, record, famous, people, player
FREX: messi, zatopek, olympic, ruth, babe, football, bolt
Lift: 0.94, 05, 07, 100m2015, 115, 19.19, 220
Score: messi, zatopek, ruth, olympic, babe, bolt, football
Topic 6 Top Words:
Highest Prob: life, da, film, freud, vinci, famous, plato
FREX: vinci, plato, bergman, columbus, wright, mao, wilbur
Lift: 10.9, 11the, 123concertospiano, 1350s, 1451, 1452, 1466
Score: plato, vinci, freud, van, gogh, leonardo, columbus