I found a SVM emotion prediction model on Github, the model is trained on text data in 5 emotion labels: joy, sad, anger, fear, and neutral. Accuracy is 72.71%.
Code
# def function for modeldef preprocess_and_tokenize(data): #remove html markup data = re.sub("(<.*?>)", "", data)#remove urls data = re.sub(r'http\S+', '', data)#remove hashtags and @names data= re.sub(r"(#[\d\w\.]+)", '', data) data= re.sub(r"(@[\d\w\.]+)", '', data)#remove punctuation and non-ascii digits data = re.sub("(\\W|\\d)", " ", data)#remove whitespace data = data.strip()# tokenization with nltk data = word_tokenize(data)# stemming with nltk porter = PorterStemmer() stem_data = [porter.stem(word) for word in data]return stem_data
Code
# load emotion prediction modelimport joblibloaded_model = joblib.load('tfidf_svm.sav')message ='like real desk virtual desk hot mess cleaning bad boy today wish luck'loaded_model.predict([message])
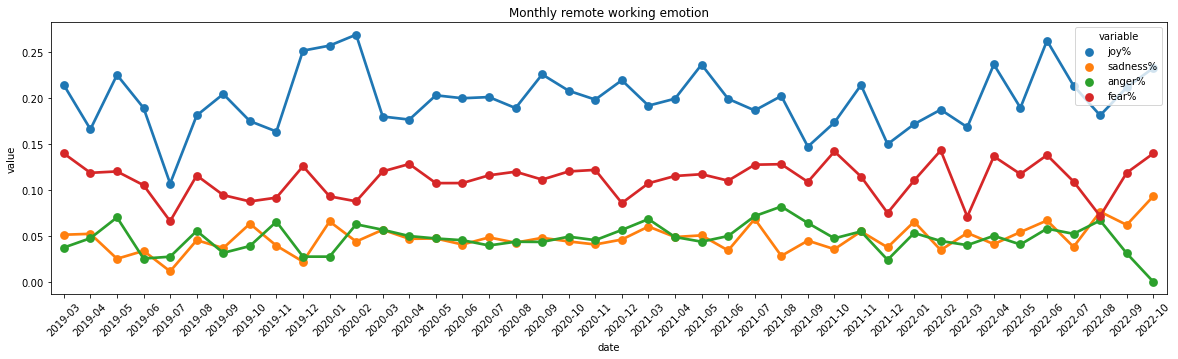
# plot monthly number of emotionsimport seaborn as snsimport matplotlib.pyplot as pltplt.figure(figsize=(20,5))sns.pointplot(x='date',y='value',data=df2, hue='variable')plt.tick_params(axis='x', labelrotation =45)plt.title("Monthly remote working emotion")
Text(0.5, 1.0, 'Monthly remote working emotion')
joy emotion slighly increased after lockdown, and it’s hard to tell from the graph.
Code
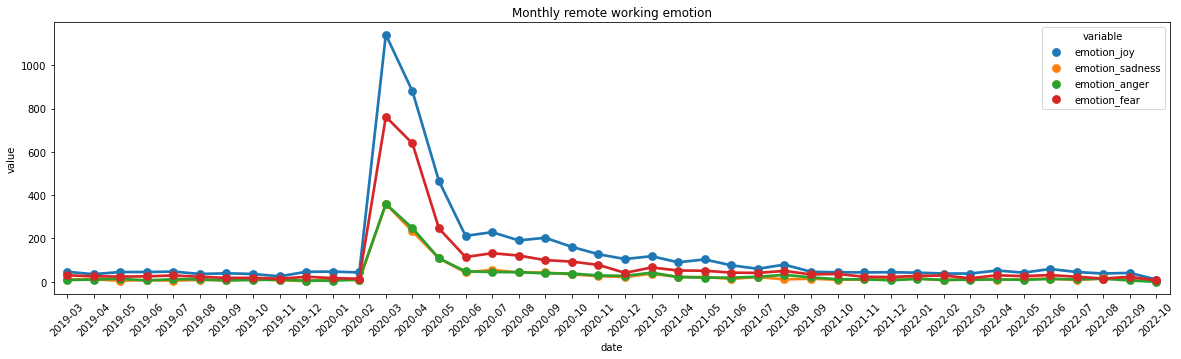
# Let's conduct t test and compare before and after lockdownfrom pandas import Timestampdf_agg_m['timestamp'] = df_agg_m['date'].apply(lambda x: x.to_timestamp().date())group1 = df_agg_m[df_agg_m['timestamp']<=datetime.date(2020, 3, 1)]group2 = df_agg_m[df_agg_m['timestamp']>=datetime.date(2020, 7, 1)]
Code
from scipy.stats import ttest_indttest_ind(group1['joy%'], group2['joy%'])
/var/folders/yn/83gzh79s0dv70yn_zgdzgg7m0000gn/T/ipykernel_62184/3391577175.py:2: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
df_ca['date'] = pd.to_datetime(df_ca['date'], errors='coerce')
/var/folders/yn/83gzh79s0dv70yn_zgdzgg7m0000gn/T/ipykernel_62184/3391577175.py:8: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
df_tx['date'] = pd.to_datetime(df_tx['date'], errors='coerce')
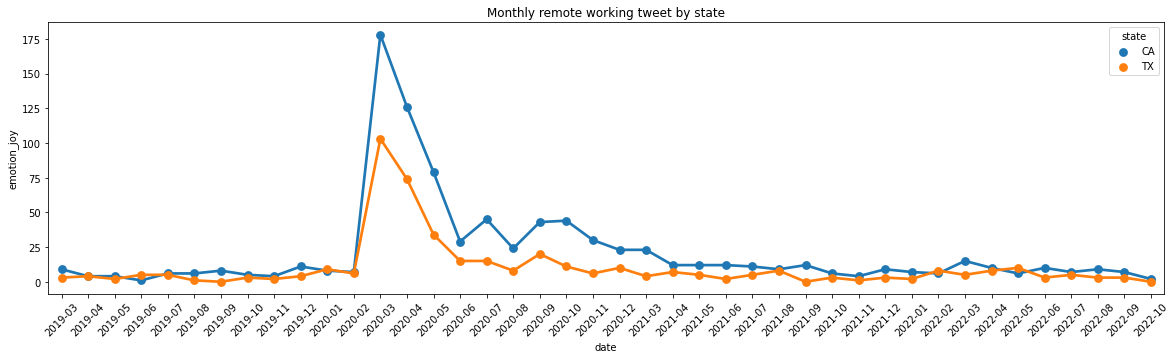
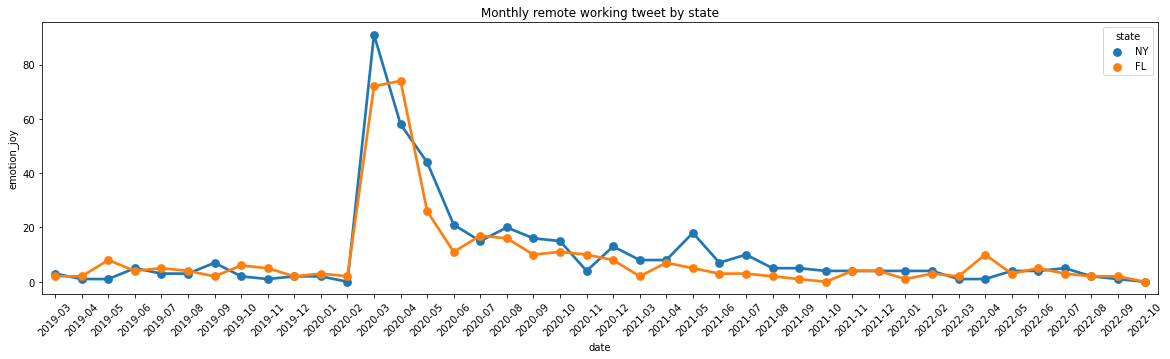
df_ca_tx = pd.melt(result, id_vars = ['date', 'tweets', 'lockdown', 'enforced_order', 'state'], value_vars = ['emotion_joy', 'emotion_sadness', 'emotion_anger', 'emotion_fear', 'emotion_neutral'])import seaborn as snsplt.figure(figsize=(20,5))sns.pointplot(x='date',y='emotion_joy',data=result, hue='state')plt.tick_params(axis='x', labelrotation =45)plt.title("Monthly remote working tweet by state")
Text(0.5, 1.0, 'Monthly remote working tweet by state')
Code
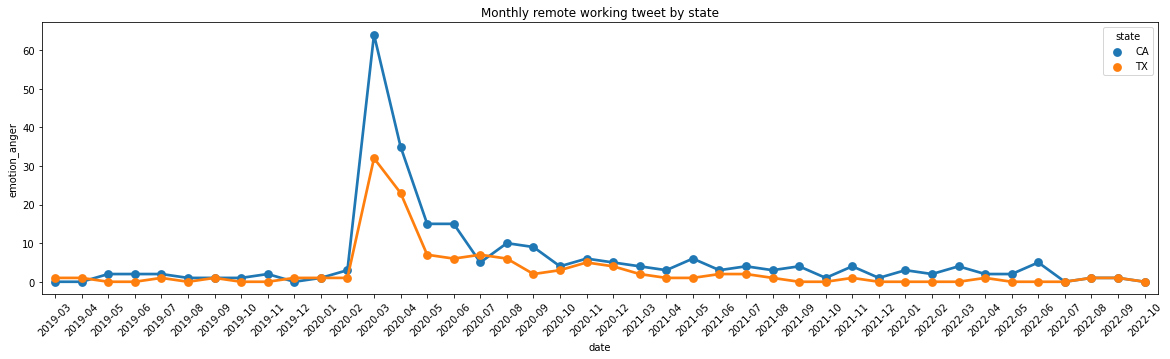
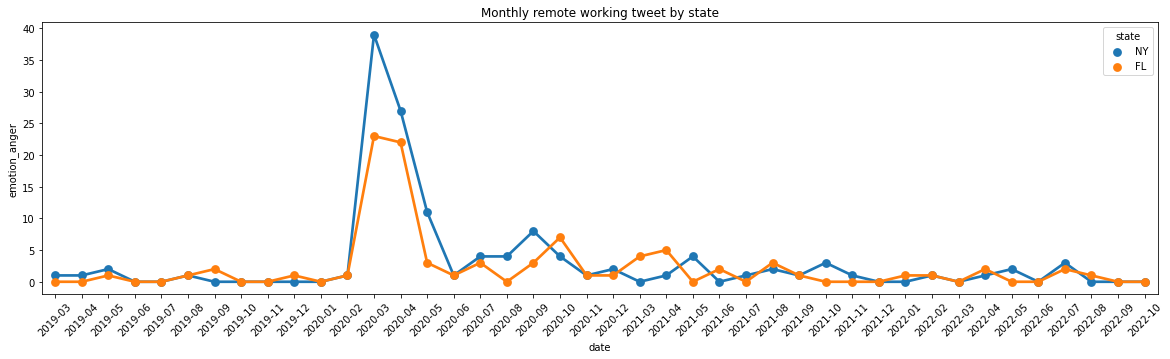
plt.figure(figsize=(20,5))sns.pointplot(x='date',y='emotion_anger',data=result, hue='state')plt.tick_params(axis='x', labelrotation =45)plt.title("Monthly remote working tweet by state")
Text(0.5, 1.0, 'Monthly remote working tweet by state')
/var/folders/yn/83gzh79s0dv70yn_zgdzgg7m0000gn/T/ipykernel_62184/1839167673.py:4: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
df_ca['date'] = pd.to_datetime(df_ca['date'], errors='coerce')
/var/folders/yn/83gzh79s0dv70yn_zgdzgg7m0000gn/T/ipykernel_62184/1839167673.py:10: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
df_tx['date'] = pd.to_datetime(df_tx['date'], errors='coerce')
index
Unnamed: 0
retweets
replies
likes
quote_count
lockdown
enforced_order
emotion_anger
emotion_fear
emotion_joy
emotion_neutral
emotion_sadness
tweets
date
state
0
0
92809.0
37.0
0.0
61.0
1.0
N
Y
1.0
1.0
3.0
10.0
0.0
15.0
2019-03
NY
1
1
99212.0
21.0
0.0
61.0
0.0
N
Y
1.0
2.0
1.0
11.0
1.0
16.0
2019-04
NY
2
2
64179.0
1.0
0.0
5.0
0.0
N
Y
2.0
1.0
1.0
6.0
0.0
10.0
2019-05
NY
3
3
85479.0
14.0
4.0
45.0
0.0
N
Y
0.0
0.0
5.0
9.0
0.0
14.0
2019-06
NY
4
4
86098.0
5.0
11.0
53.0
2.0
N
Y
0.0
1.0
3.0
10.0
0.0
14.0
2019-07
NY
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
79
37
144717.0
5.0
5.0
36.0
0.0
N
N
0.0
2.0
5.0
6.0
0.0
13.0
2022-06
FL
80
38
266912.0
17.0
31.0
149.0
1.0
N
N
2.0
1.0
3.0
17.0
1.0
24.0
2022-07
FL
81
39
110891.0
2.0
1.0
25.0
1.0
N
N
1.0
0.0
2.0
7.0
0.0
10.0
2022-08
FL
82
40
144279.0
10.0
6.0
70.0
0.0
N
N
0.0
1.0
2.0
9.0
1.0
13.0
2022-09
FL
83
41
22074.0
1.0
0.0
2.0
0.0
N
N
0.0
0.0
0.0
2.0
0.0
2.0
2022-10
FL
84 rows × 16 columns
Code
df_ca_tx = pd.melt(result, id_vars = ['date', 'tweets', 'lockdown', 'enforced_order', 'state'], value_vars = ['emotion_joy', 'emotion_sadness', 'emotion_anger', 'emotion_fear', 'emotion_neutral'])import seaborn as snsplt.figure(figsize=(20,5))sns.pointplot(x='date',y='emotion_joy',data=result, hue='state')plt.tick_params(axis='x', labelrotation =45)plt.title("Monthly remote working tweet by state")
Text(0.5, 1.0, 'Monthly remote working tweet by state')
Code
plt.figure(figsize=(20,5))sns.pointplot(x='date',y='emotion_anger',data=result, hue='state')plt.tick_params(axis='x', labelrotation =45)plt.title("Monthly remote working tweet by state")
Text(0.5, 1.0, 'Monthly remote working tweet by state')